

【システム担当者必見】ネットワーク障害対応の基本手順
こんにちは。クレスコデジタルテクノロジーズのM.Kです。
私は未経験から職業訓練校を経て、ネットワークエンジニアとして金融機関のネットワーク維持管理業務・データセンター移転業務に1年半従事してきました。
ネットワークを維持・管理することは、安定した金融サービスを提供する上で欠かせない重要な業務です。しかし、どれだけ注意深く運用しても、想定外の障害が発生してしまうことがあります。
そこで当記事では、ネットワーク障害が発生した時の基本的な対応手順を、実際のケースを交えながら解説していきます。
■あわせて読まれている資料:
対応事例やネットワークサービス一覧を掲載!
→ネットワークテクノロジーサービス
目次[非表示]
- 1.障害対応の基本
- 2.障害発生から恒久対応までの手順
- 3.pingを使った障害箇所の特定
- 4.冗長構成特有の障害 ~HSRPフラッピング~
- 5.まとめ
- 6.引用元
障害対応の基本
障害対応で大切なことは、現状を正確に把握することです。
特に、データセンターに構築される大規模ネットワークでは、その広大さから障害発生時の原因がどこにあるのかを把握することが難しくなります。
例として「社内PCからインターネットに接続ができない」という障害が発生した場合を考えてみると、その原因がネットワークにあるのか、通信機器にあるのか、端末本体に原因があるのかは調べてみないとわかりません。
ネットワーク障害が発生した時には、広大なネットワークの中を調査し、事象の切り分けや対応を行うことで早期復旧と再発防止を目指します。
※客先常駐で維持管理業務を行う場合、「お客様所有物のネットワーク機器とその運用管理をさせて頂いている」という立場上、ネットワーク調査や機器の設定変更を独断で行うことありません。障害対応の際は、お客様への状況報告とお客様からの指示に基づく作業を正確に行い、お客様から意見を求められた際には専門家としてその時に考えられる最善の方法を提案する技術力が求められます。
障害発生から恒久対応までの手順
障害が発生したことは、監視サーバや監視チームからの障害発生連絡、関連会社や利用者からの問い合わせ等で発覚することが多いです。障害発生時にどの部署に連絡すべきか、その後の対応はどのような順序で承認、実施される必要があるのかをあらかじめ「障害対応マニュアル」に記載し、周知しておくことが重要です。
障害発生の連絡と、それに対する対応依頼が維持管理部門にまで届いた後は、以下の手順で対応します。
① 障害ケースの切り分け
障害の種類を分類し、それぞれに適した対応を行います。
具体的な障害ケースには、次のようなものがあります。
- ネットワークが繋がらない
- 特定のサービスを利用できない
- 通信の遅延や失敗が繰り返し起きている
- 特定の機器を利用できない
② 障害状況の把握
障害発生時の状況や影響範囲の把握が大切です。
以下の情報を収集し、原因の特定や被害拡大の防止に役立てます。
- 障害が発生したサービスやネットワークの範囲
- 障害が発生して影響を被っている利用者、拠点、機器
- 障害発生日時(いつから発生したか、再現性があるか、頻度はどのくらいか)
- 障害発生前に変更した内容(ネットワーク構成やソフトウエアなど)
- 障害発生と同時期に行っていた作業記録
- 現在の状況(障害発生が継続しているか、復旧済みか)
③ 障害対応記録の確認
過去に同様の事象が発生し、対応記録が残っている場合は、それを活用して迅速な対応を行います。
④ 暫定対応
障害の復旧に時間がかかる場合や、被害拡大を即時に防ぐ必要がある場合、あるいは根本原因の特定を行うために、暫定的な対応を実施します。
※この暫定対応のことを【ワークアラウンド】とも呼びます。例として、主系回線に障害が発生した場合にバックアップ回線に切り替えて運用を継続するフェイルオーバーや、通信過多による帯域不足解消のため重要な通信のみを継続させる縮退運転などがあります。
⑤ 恒久対応
原因が特定された後、再発を防ぐための恒久的な対応を行います。
機器の増強や交換が必要で、即時の対応が難しい場合には、暫定対応を併用しながら段階的に切り替えを進めます。
また、再発防止と同様の事態事象が発生した際の迅速な対応を目的として、発生原因や対処の経緯を報告書に纏めます。
■あわせて読まれている資料:
ネットワークの状態を可視化しトラブル解決をサポート
→ネットワーク調査サービス
pingを使った障害箇所の特定
ここでは、障害箇所の特定手段の一つであるping機能について触れます。
ping機能はICMPタイプ8のエコー要求パケットとタイプ0のエコー応答パケットを使用し、OSI参照モデル第1層(物理層)から第3層(ネットワーク層)でのネットワークの疎通確認やデータの損失、遅延の有無を調べるためのソフトウエアです。【図.1参照】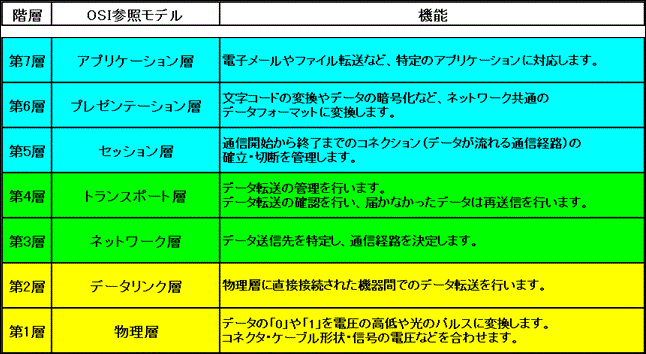
図.1 OSI参照モデルとその機能
ping機能はPCやネットワーク機器に標準搭載されており、ネットワーク監視においては定期的にpingを送信し続けることで障害の発生を検知する用途(死活監視)でも活用されます。
以下では、pingを使った障害箇所の特定方法について具体的な手順を解説します。【図.2参照】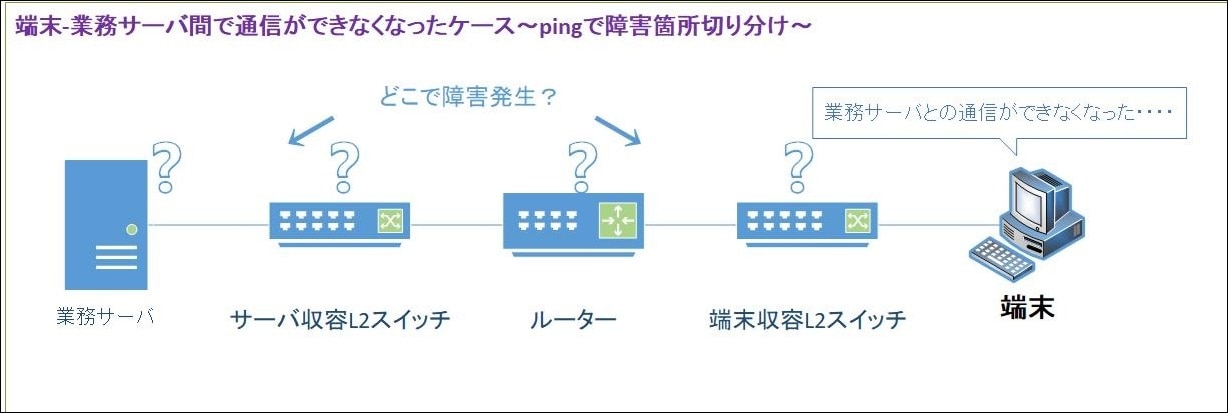
図.2 端末―業務サーバ間の通信障害ケース
図.2のように、ある日突然端末から業務サーバへ通信できなくなったとします。
外見上はケーブルや機器に異常は見られません。
このような場合、ping を使用することで、物理層~ネットワーク層のどこが原因で通信が途絶えているのかを調べることができます。
① 端末から業務サーバへの ping 実施
端末のコマンドプロンプトを開き、次のコマンドを入力します。
【ping [宛先の機器のIPアドレス]】(ここでは業務サーバのIPアドレス192.168.1.1を使用)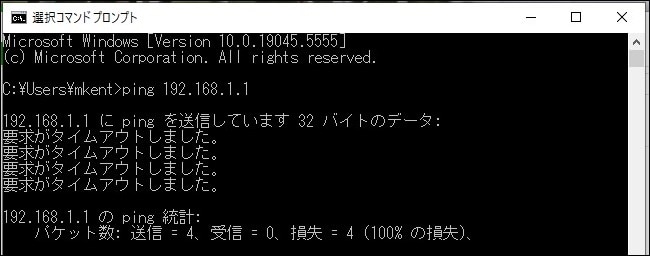
図.3 コマンドプロンプトping送信画面
② ping結果を確認
- 応答あり:端末~業務サーバまでの物理層~ネットワーク層通信は正常
- 応答なし:どこかで通信が途絶えている可能性がある
ping の結果、「要求がタイムアウトしました(Request timed out)」と表示された場合、ICMP エコー要求が業務サーバに届いていないことを意味します。【図.3, 図.4 参照】
※ ただし、サーバ側で ICMP エコー応答を無効化している場合は例外です。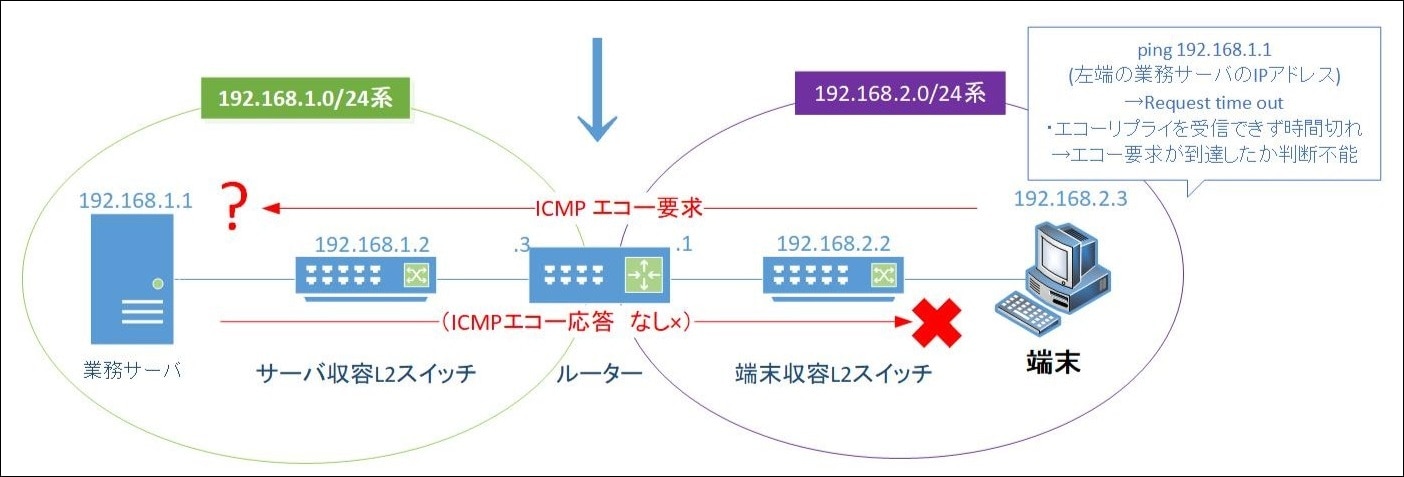
図.4 ICMPエコー要求 応答なし
日本語表記では「要求がタイムアウトしました」、英語表記では「Request time out」と表示されます。これは、ICMPエコー要求が宛先IPアドレスに届いていない場合に表示されるメッセージです。
③ サーバ収容L2スイッチへの ping
次に、業務サーバの1つ手前にあるサーバ収容L2スイッチへ ping を送信します。
(ここでは サーバ収容L2スイッチの IP アドレス 192.168.1.2 を使用)(図.5)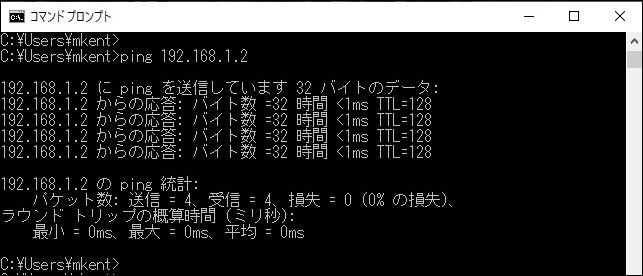
図.5 ICMPエコーリプライ受信
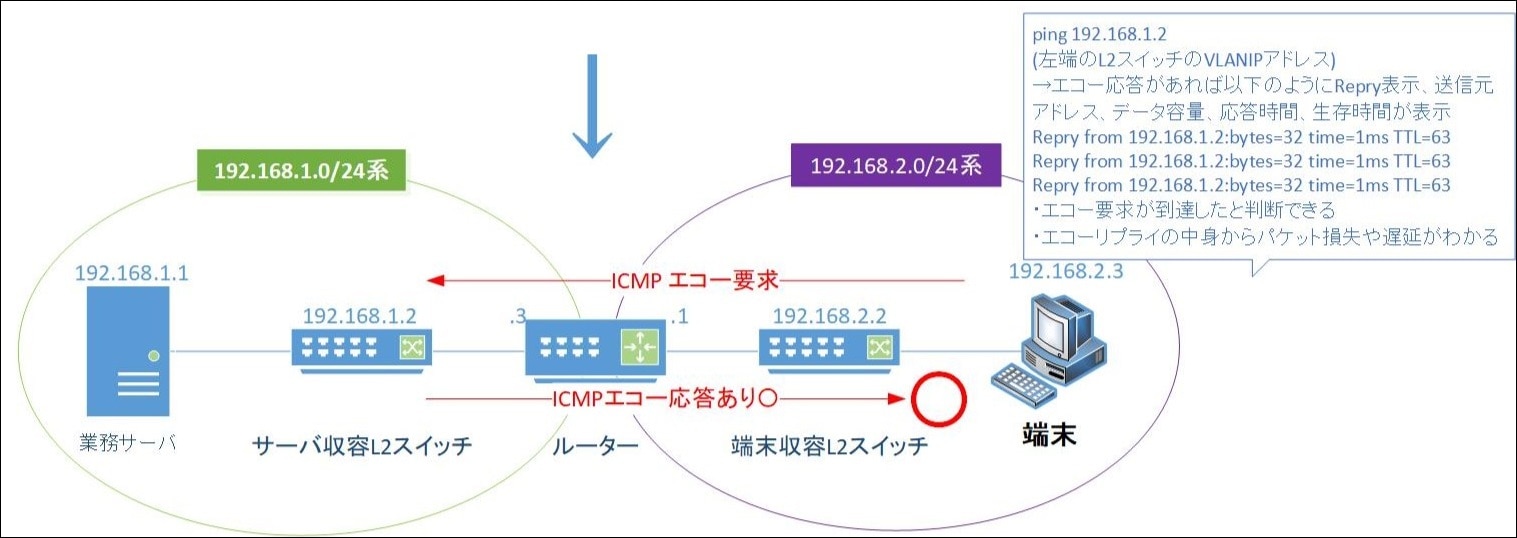
図.6 サーバ収容L2スイッチに対するping エコーリプライあり
④ ping結果を確認
- 応答あり: 端末~サーバ収容L2スイッチ間の通信は正常
- 応答なし: 業務サーバ~サーバ収容L2スイッチ間のどこかで障害が発生している可能性がある
上記図.5、図.6では業務サーバ手前のサーバ収容L2スイッチに対してはpingが成功し、サーバ収容L2スイッチから端末に対してのICMPエコーリプライが帰ってきています。
図.7 pingによる障害箇所の推定切り分け図
⑤ ping の結果から障害原因を絞り込む
pingの結果を分析することで、L2スイッチから端末までの経路において物理層~ネットワーク層の通信が正常であるかどうかを確認できます。
また、pingが失敗した際に表示されるメッセージをもとに、原因を以下のように絞り込むことができます。
■ Request time out <要求がタイムアウトしました>
- ファイアウォールによりICMP通信が制限されている (Windowsではデフォルトで有効)
- ルーターで宛先IPアドレスが制限されている
- ケーブルの物理的な破断
- IPアドレスの間違い
本ケースでは、「要求がタイムアウトしました」と表示されたため、上記のいずれかが原因である可能性が高いことが分かります。
■ Destination net unreachable<宛先ネットワークに到達できません>
- ルーターには到達しているが、その先のネットワークに到達していない
- ルーターに宛先のルーティング設定が入っていない
- ルーターのアクセスリスト(ACL)によりICMP通信がブロックされている
■ Destination host unreachable<宛先ホストに到達できません>
- ルーターには到達し、宛先ネットワークにも到達しているが、そこから先の宛先ホストに到達できない。
- 該当宛先ホストがいない(宛先機器が停止している、または ネットワークインターフェースカードが無効になっている)
以上を踏まえてping を利用することで、障害の発生箇所を物理層~ネットワーク層レベルで特定することができます。本ケースでは、調査の結果 「業務サーバ~L2スイッチ間で障害が発生している」 ことがわかります。ping の結果を適切に分析することで、障害の原因を段階的に絞り込むことが可能になります。
冗長構成特有の障害 ~HSRPフラッピング~
前述のpingを使った障害箇所の特定では、ネットワークの構成が【シングル構成】であることを前提としていました。
シングル構成とは、末端同士を1本の経路で結ぶ構成のことであり、この構成では、経路上の機器やケーブルのいずれかに障害が発生すると、通信に直接的な影響を与えてしまいます。
そのため、業務用ネットワークや金融機関などの大規模ネットワークでは、一般的にシングル構成を二重化した【冗長構成】が採用されています(図.8参照)。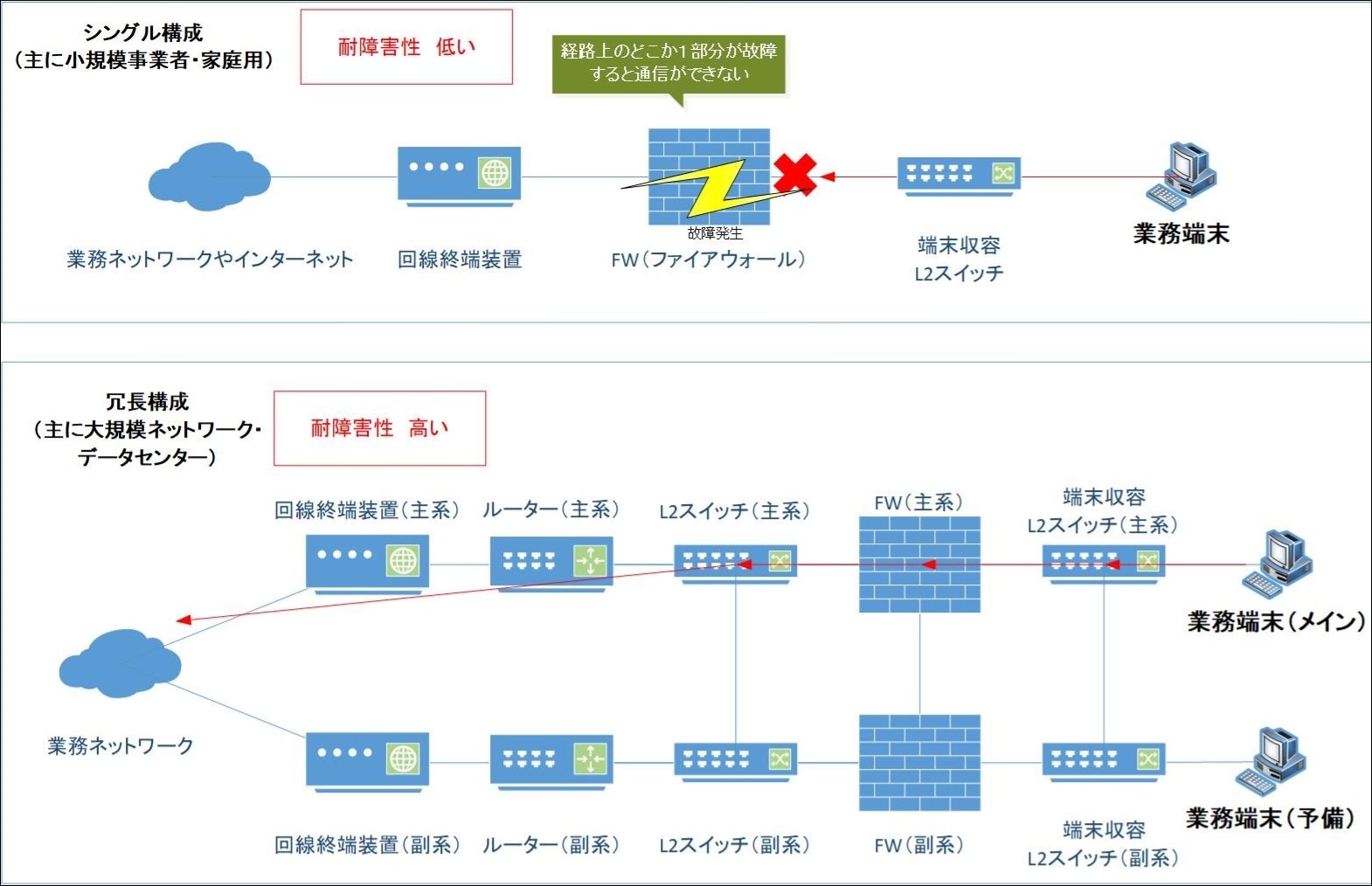
図.8 シングル構成と冗長構成の比較
冗長構成では、特定の機器が故障した場合でも、HSRP機能やフェイルオーバー機能により自動的に予備系へ切り替わることで、通信の継続が可能となります(図.9参照)。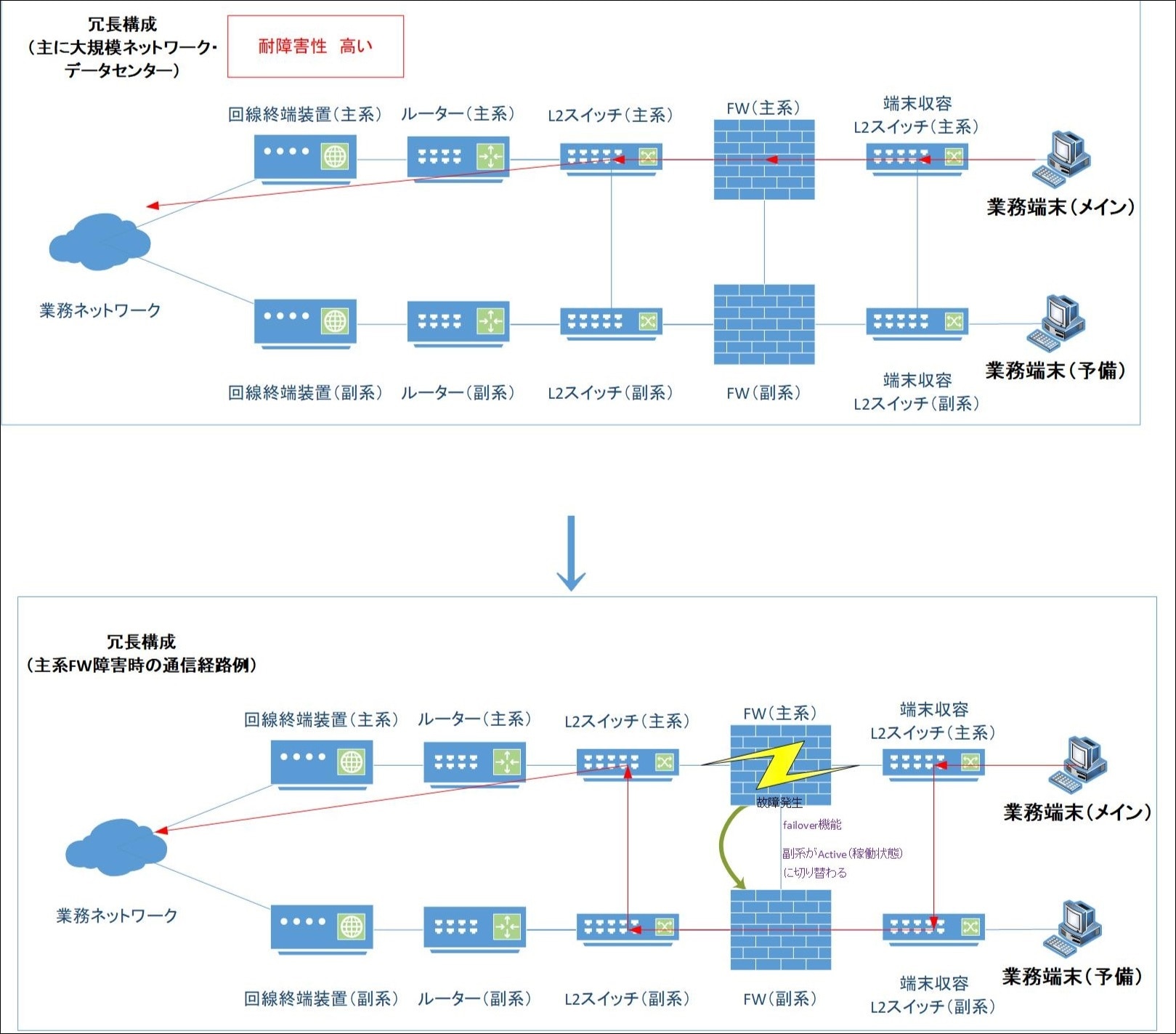
図.9 冗長構成 FW故障時の状態遷移図
補足:HSRP とは?
HSRP(Hot Standby Router Protocol)は、2台以上のルーターを使用してデフォルトゲートウェイを冗長化する技術で、Cisco社独自のプロトコルです。一般的には2台構成で、1台がアクティブ(Active)として通信を処理し、もう1台がスタンバイ(Standby)として待機します。
この2台は、お互いに3秒ごとにHSRP Helloパケットを送信し合い、対向機からのHelloパケットが一定時間(デフォルト10秒間)受信できなくなると、スタンバイルーターがアクティブに昇格することで通信を継続します。
しかし、何らかの原因で短時間のうちにアクティブとスタンバイが頻繁に切り替わる「HSRPフラッピング」や、両方の機器が同時にActive状態になってしまう「HSRPスプリットブレイン(Split Brain)」という障害が発生することがあります。
このような状態になると、
- ネットワーク内でルーティングの不整合が発生
- パケットロスや通信の不安定化
- ルーターのCPU使用率の急上昇
などの問題が生じる可能性があります。
弊社の2025年2月6日寄稿のDTブログにて詳しく紹介しておりますので是非ご参照ください。
しかし、冗長構成だからといって必ずしも安定しているとは限りません。
ここでは、冗長構成ならではの障害の一例である「HSRPフラッピング」について、実際の障害対応事例をもとに解説します。
以下図.10は、HSRPフラッピングが発生したネットワーク構成の概要です。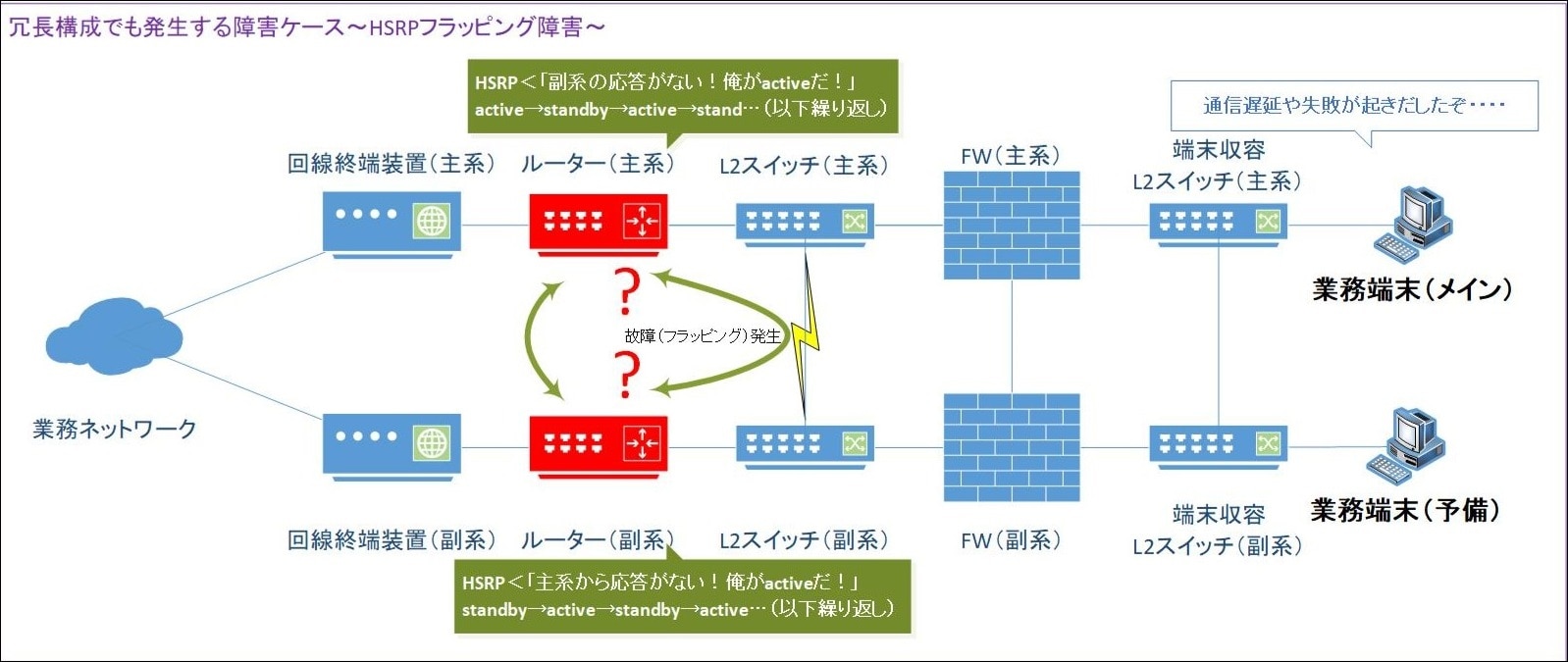
図.10 HSRPフラッピング現象の発生図
本来はルーター(主系)が業務通信の制御を行い、ルーター(副系)は Standbyとして待機する構成ですが、HSRPフラッピングが発生したことで、各ルーターのCPU使用率が激増し、業務端末の通信が不安定になる障害が発生しました。
まず、障害の影響を最小限に抑えるため、ルーター(副系)と接続されていたL2スイッチ(副系)のポートを閉塞することでルーター(副系)への通信を遮断しました。
これにより、ルーターのCPU使用率の鎮静化を確認できました。
その後ルーター、L2スイッチ等機器のログを確認しました。
※機器のCPU使用率が高騰すると、SSH接続やpingが困難になり、ログ取得やスイッチへのアクセスも制限されるため、このような一時的な遮断措置が有効です。
L2スイッチ(副系)のポートシャットダウンでルーターのCPU使用率が低下したこと、ルーター(副系)やその他機器に問題が見られなかったことから、L2スイッチ(副系)の故障ないしリンク障害によるHelloパケット送信障害が影響していると考えました。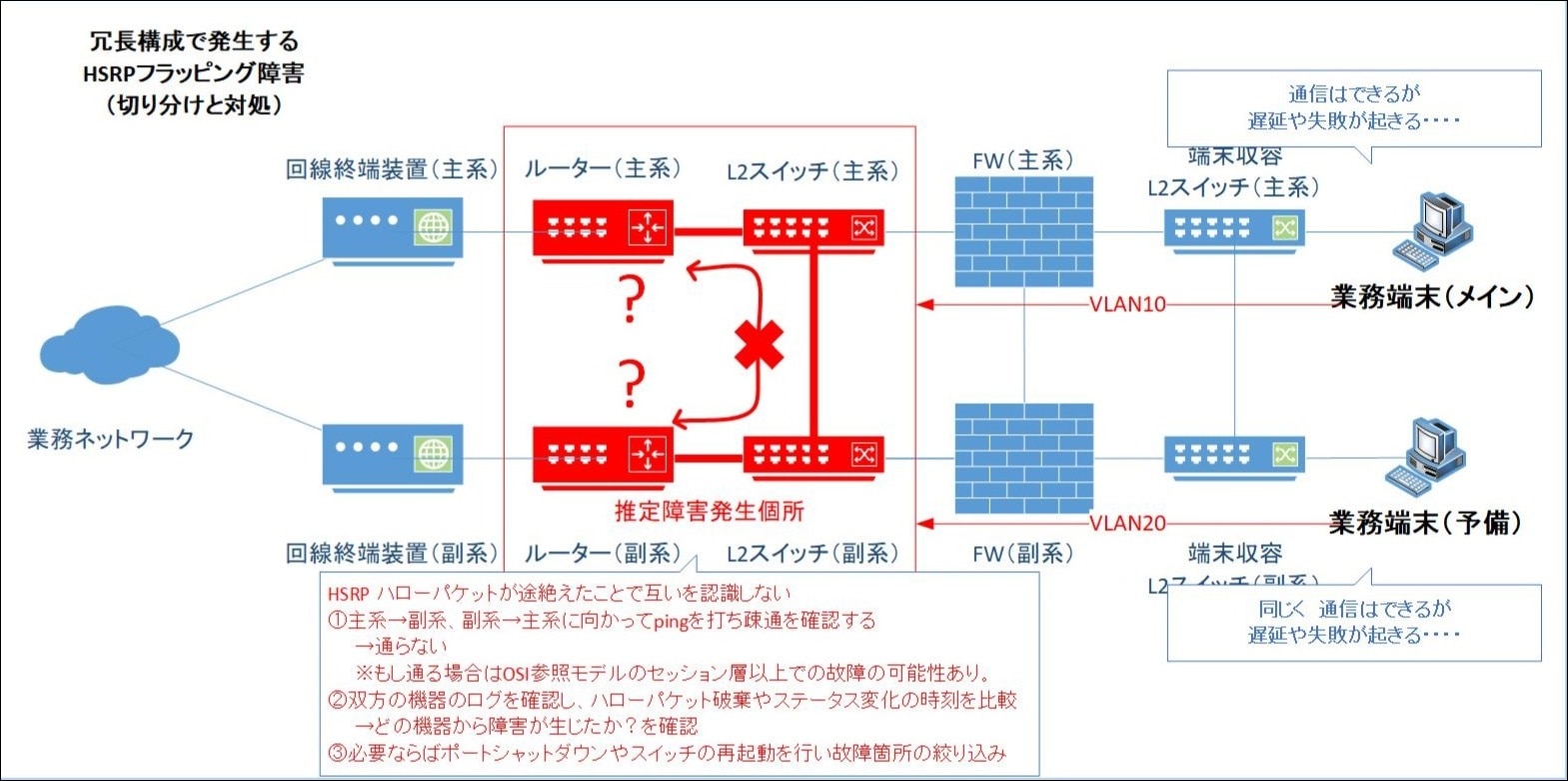
図.11 初期の障害発生推定箇所
対応としては、L2スイッチ(副系)をネットワークから切り離し、主系機器のみによる縮退運転とし、後日L2スイッチ(副系)を新品の機器に交換しました。
以下 図.12はL2スイッチ(副系)のポートシャットダウンによる通信への影響を示しています。
予備の業務端末はL2スイッチ(副系)遮断の影響で通信不能ですが、主系経路を使った主系端末からの業務通信は安定稼働を維持しました。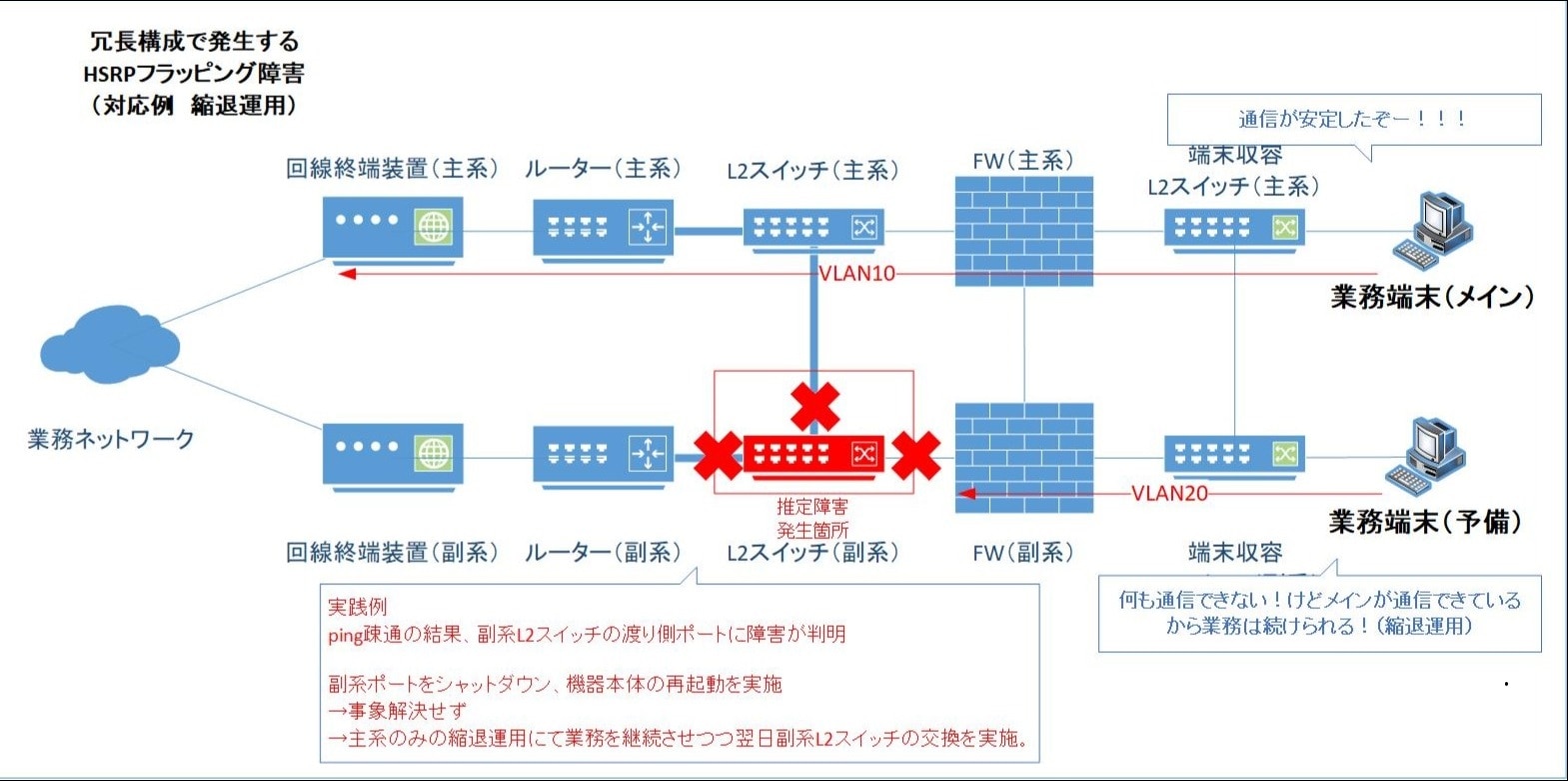
図.12 フラッピング現象暫定対応後のネットワーク図
本障害への対応を通じて、冗長構成であっても通信障害が発生すること、また業務通信の復旧を優先するために、早期に異常箇所を切り離す対応も有効であることを学びました。
駆け出しだった当時の私にとって、非常に印象的な経験でした。
まとめ
ネットワークの世界では、新しいOSのバグが見つかったり、原因不明の障害が発生したかと思えば、機器を再起動するだけでなぜか復旧したりすることがよくあります。こうした障害の発生機序や現象のすべてを正確に理解するのは簡単ではありません。
この記事を通じて私自身の障害対応の経験や知識を共有することで、これからネットワークエンジニアとしての経験を積み重ねる皆さんのお役に立てればと思います。少しでも参考になれば幸いです。
ネットワークエンジニアにとって障害対応のスキルを高めることは重要ですが、障害を未然に防ぐことや、それを支える仕組みを作ることの方がさらに重要です。日々の運用監視や定期的なメンテナンスを通じて、ネットワークを安定して稼働させることこそが、ネットワークエンジニアに求められる最大の役割ではないでしょうか。
最後までお読みいただき、ありがとうございました。
■あわせて読まれている資料:
ネットワークの状態を可視化しトラブル解決をサポート
→ネットワーク調査サービス
■サービス資料一覧はこちら↓
引用元







